본 포스팅은 Abraham Silberschatz 저 『Operating System Concepts』(9th Edition)의 내용을 개인 학습 목적으로 요약·정리한 글입니다.
6.1 배경
명령어의 수준 분류
-
기계 명령어
- 0과 1로 구성된 이진 코드
-
어셈블리 언어
- 기계 명령어를 사람이 읽을 수 있도록 표현한 것 (
Move R3, Add R1 R2, ...) - 각 어셈블리 명렁어는 하나의 머신 명령어로 변환된다
- 기계 명령어를 사람이 읽을 수 있도록 표현한 것 (
-
고급 언어
- 컴파일러에 의해 변환, 대부분의 고급 언어 명령어는 여러 개의 머신 명령어로 변환된다.
동시성 문제
-
프로세스는 병행적으로(concurrently) 실행될 수 있음
- 프로세스는 어느 지점에서나 인터럽트되어 실행이 부분적으로 완료될 수 있음
- 공유 데이터에 대한 동시 접근은 데이터 불일치(=데이터 무결성 문제)를 초래할 수 있음
생산자-소비자 문제
-
생산자 코드
-
소비자 코드

* 오류 → 진입 차단 조건문이 (counter == 0) 이어야 올바름 - 오류 → 진입 차단 조건문이 (counter == 0) 이어야 올바름
-
counter 변수를 0으로 초기화한다. 생산자가 버퍼에 새 항목을 추가할 때마다 counter 값을 증가시키고, 꺼낼 때 감소시킨다.
- counter가 0이면 → 버퍼가 비어 있음 (소비자는 기다려야 함)
- counter가 BUFFER_SIZE 이면 → 버퍼가 가득 참 (생산자는 기다려야 함)
-
그러나, 생산자와 소비자의 개별적 코드가 올바를지라도, 병행적으로 실행 시 올바르게 동작하지 않는다.
-
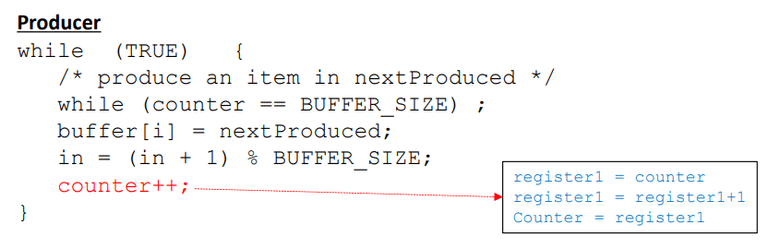
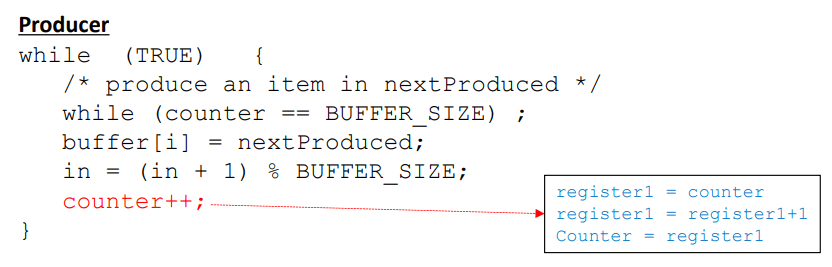
예를 들어, counter의 현재 값은 5라고 가정하자. 생산자와 소비자가 counter++ 및 counter--를 병행하게 실행하면 counter는 4나 5나 6이 될 수 있다.

- 가령 두 프로세스는 동일한 프로세서에서 실행되어 동일한 물리적 CPU와 레지스터에 의해 연산된다고 하더라도, Context Switch에 의해 현재 상태가 메모리에 보관되었다가 다시 적재된다는 것을 상기해야 한다. 따라서 싱글 프로세서 상의 동일한 누산기(accumulator)에서의 작업이라고 가정하더라도, 상기 순서도에서의 처리는 R1과 R2로 구분되어 동작한다고 볼 수 있다.
- 생산자와 소비자는 초기 counter의 값 5에서 각각 더하고 빼는 작업을 한 번씩 실행하였으니, 최종 값은 다시 5가 되어야 한다. 그러나, 해당 코드를 실행하고 마친 뒤 전역변수 counter의 값은 에서 4가 되어 끝마친다.
- 만약 와 의 순서를 뒤바꾼다면 counter의 값은 6이 된다.
-
- 결국 생산자-소비자 문제는 이러한 경쟁 조건(Race Condition) 속에서 접근 발생 순서에 의존한 부정확한 상태에 도달하게 한다.


6.2 임계 구역(Critical Section) 문제
임계 구역
-
임계 구역(Critical Section)이란 공유 변수 변경, 테이블 업데이트, 파일 쓰기 등이 이루어지는 코드의 일부분을 말한다.
- 여러 프로세스가 공통 자원에 접근할 수 있는 취약 구간에 해당한다.
// Producer while (TRUE) { /* nextProduced에 아이템을 생성 */ while (counter == BUFFER_SIZE); // 버퍼가 가득 찰 때까지 기다림 buffer[i] = nextProduced; in = (in + 1) % BUFFER_SIZE; counter++; // ← 🔴 크리티컬 섹션 }
코드 구역 종류

- 진입 구역 (Entry Section) : 임계 구역에 들어가기 위해 허락을 요청하는 코드 구역
- 임계 구역 (Critical Section) : 다른 프로세스와 공유하는 지원을 갱신하거나 접근하는 구역
- 퇴출 구역 (Exit Section) : 임계 구역에서 나오는 구역
- 나머지 구역 (Remainder Section) : 진입·임계·퇴출 구역을 제외한 나머지 구역
임계구역 문제 해결안
-
상호 배제 (Mutual Exclusion)
- 프로세스 가 Critical Section에서 실행 중일 때에는, 다른 어떤 프로세스도 동시에 그들 자신의 Critical Section에서 동시에 실행중일 수 없다.
-
진행성 (Progress)
- 시스템에 한 번이라도 진입을 원하는 프로세스가 있다면, 현재 누군가가 임계 구역을 사용 중이지 않을 때 그들 중 최소한 한 프로세스는 반드시 임계 구역에 진입할 기회를 가져야 한다.
- 즉, “누군가"는 항상 전진할 수 있도록 결정 과정이 무한히 지연되어서는 안 된다.
-
한정된 대기 (Bounded Waiting)
- 어떤 프로세스가 Critical Section에 들어가기를 요청한 뒤, 그 요청이 허용되기 전까지 다른 프로세스들이 Critical Section에 들어갈 수 있는 횟수에는 제한이 있어야 한다.
- 즉, 어떤 프로세스도 무한정 기다리는 일은 없어야 한다.
한정된 대기(Bounded Waiting)와 진행성(Progress) 의 차이
-
한정된 대기의 경우 ‘어떤 프로세스가 요청을 했을 때, 유한한 횟수 안에 반드시 진입할 수 있어야 함’을 의미함. (즉, fairness에 대한 조건)
- ‘개별 프로세스가 공정한 진입을 보장받을 수 있는가’에 초점이 맞추어짐
-
진행성의 경우 ‘프로세스가 CPU에 계속 진입하여 진행되고 있어야 함’을 의미함. (즉, liveness에 대한 조건)
- 즉, CPU가 계속 손바뀜이 되고 있는가를 보장하는 것에 초점이 맞추어짐
-
특정 스레드가 굶주리더라도, 전체 시스템이 멈추지 않으면 만족했다고 볼 수 있음
-
세 가지 요구조건은 다음의 조건을 가정한다.
- 각 프로세스는 0이 아닌 속도로 실행됨 (즉, 어떤 프로세스도 무한히 정지해 있거나 멈추지 않음)
- n개의 프로세스들간의 상대적인 속도에 대한 가정은 하지 않음 (프로세스 간 속도의 차이가 있을 수는 있지만, 그것이 알고리즘의 정확성에 영향을 주어서는 안됨) → 즉, 공정성에 관한 이야기
경쟁 조건과 운영체제 개발
-
선점형 커널과 비선점형 커널
-
선점형 커널 : 커널 모드에서 수행되는 동안 프로세스의 선점을 허용함 → 동기화 문제가 발생할 여지가 있음
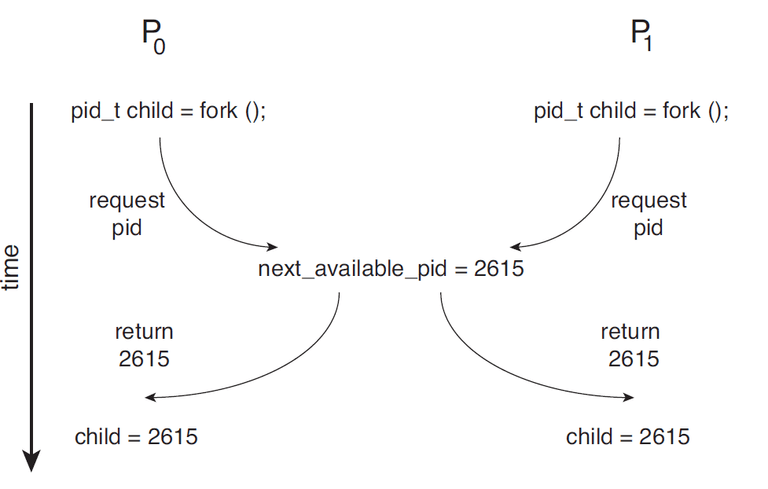
img1.daumcdn.png - 선점형 커널에서는 두 프로세스가 동시에
fork()를 호출하여, 동일한 PID를 가진 자식 프로세스를 생성할 가능성이 있다.
- 선점형 커널에서는 두 프로세스가 동시에
-
비선점형 커널 : 커널 모드에서 수행되는 동안 Context Switch가 일어나지 않아 프로세스의 선점을 허용하지 않음 → 경쟁 조건을 고려하지 않아도 됨
- 대표적으로 아래의 “인터럽트 기반 솔루션” 이 해당됨
-
- 그러나 비선점형 커널의 경우 프로세스가 지나치게 오랫동안 실행될 위험, 실시간 프로그래밍에 부적합함 등의 이유로 선점형 커널이 선호됨
인터럽트 기반 솔루션
-
인터럽트 기반 솔루션(Interrupt-based Solution)은 비선점형 방식에 해당함
- 진입 구간에서 인터럽트를 비활성화(disable)하고, 종료 구간에서 인터럽트를 다시 활성화(enable)한다.
-
인터럽트 기반 솔루션의 문제
-
Critical Section이 1시간동안, 또는 기약 없이 실행된다면?
- 어떤 프로세스는 굶주릴 수 있다 — Critical Section에 절대 진입하지 못할 수도 있음
-
멀티 프로세서 환경에서 부적절 → 한 CPU에서 인터럽트를 껐다고 해서, 다른 CPU까지 제어할 수는 없음.
- 멀티 프로세서 환경에서는 전혀 통제되지 않음
-
6.3 피터슨 솔루션
- 임계구역에 대한 고전적인 소프트웨어 기반 해결책
-
피터슨 솔루션은 임계 구역과 나머지 구역을 번갈아 실행하는 두 개의 프로세스 과 로 한정한다.
- 또는, 를 항상 만족한다는 가정 아래에서 와 로 나타낼 수도 있다.
-
두 개의 프로세스를 위한 해법
int turn; boolean flag[2];int turn: 프로세스의 차례를 의미한다. 만약 turn = 0 이라면 0번째 프로세스()를 의미한다.boolean flag[2]: 각 프로세스가 크리티컬 섹션에 들어갈 의향이 있는지 표시. 만약 flag[1] 이 참(true)이라면 이 임계구역으로 진입할 준비를 마쳤음을 의미한다.
- 피터슨 솔루션에서 Pi, Pj의 구조


피터슨 솔루션의 증명
-
상호 배제(Mutual Exclusion)
- 프로세스 가 크리티컬 섹션에 들어가기 위해서는
flag[j] == FALSE(상대방이 들어가고 싶지 않아 함) 또는turn == i(우선권이 나에게 있음) 이어야 함 - 만약, 와 가 동시에 크리티컬 섹션에 들어갈 수 있다면
flag[i] == True&&flag[j] == True여야 함 → 가능한 케이스 -
하지만 와 가 동시에 while 조건을 통과할 수는 없다.
- 두 프로세스가 동시에 크리티컬 섹션 진입을 요청할 수는 있다
- 그러나 turn 변수의 값은 한 시점에 i 이거나, 또는 j 이거나 둘 중 하나이다.
- 따라서 while 조건문을 pass 할 수 있는 건 또는 이며, 둘 다일 수 없다.
- 프로세스 가 크리티컬 섹션에 들어가기 위해서는
-
진행성(Progress) 및 한정된 대기(Bounded Waiting)
-
만약 가 크리티컬 섹션에 들어갈 준비가 안 되었다면
→
flag[j] == FALSE→ 이 경우 는 바로 크리티컬 섹션에 진입 가능
-
만약 가
flag[j] = TRUE로 설정했고, 현재 while 루프 안에서 대기 중이라면:turn == i→ 가 크리티컬 섹션에 들어감turn == j→ 가 크리티컬 섹션에 들어감
-
한 프로세스가 크리티컬 섹션을 빠져나올 때,
flag[j] = FALSE로 설정됨 → 그 다음엔Pᵢ가 들어갈 수 있음 -
만약
Pⱼ가 다시flag[j] = TRUE로 바꾼다면,반드시
turn = i로 설정해야 함 -
이때
Pᵢ는 while 루프 안에서turn값을 바꾸지 않으므로,Pⱼ가 최대 한 번만 크리티컬 섹션에 진입한 후에는Pᵢ도 반드시 크리티컬 섹션에 진입할 수 있음
-
피터슨 솔루션의 한계
-
피터슨 솔루션은 현대 아키텍처에서 항상 동작한다고 보장할 수 없다.
- 피터슨 솔루션에서는
LOAD또는STORE등의 명령어가 모두 원자성을 가진다(atomic)고 가정 - 즉, 실행 중에 인터럽트되지 않는다고 본다.
- 현대 컴퓨터 구조에서는 이러한 기초적인 명령어조차도 원자성을 보장하지 않을 수 있다. (컴파일러 최적화, 캐시 일관성, 명령 재배치 등의 요인으로 인함)
- 따라서, 피터슨 알고리즘은 이론적으로 타당하지만, 실제 적용에서는 보장할 수 없다.
- 피터슨 솔루션에서는
-
예시 상황 1
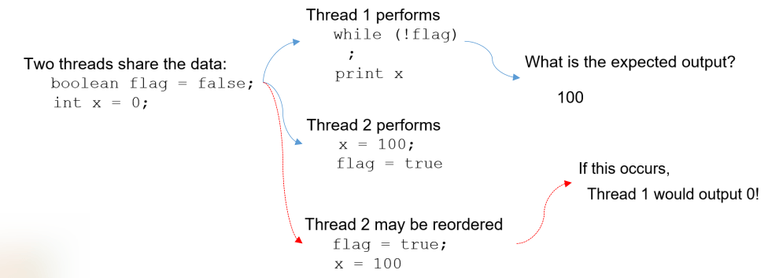
flag = true가 먼저 실행되어 Thread 1이 루프를 빠져나오고-
그 순간 아직
x = 100이 실행되지 않았기 때문에→
x = 0출력될 수 있음
-
예시 상황 2
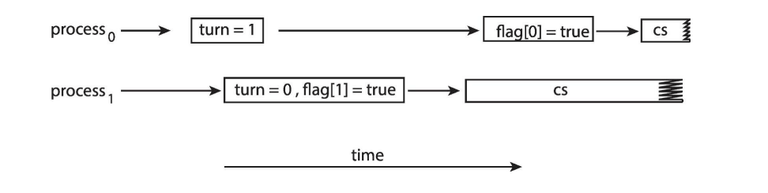
-
두 프로세스가 동시에 크리티컬 섹션에 진입하게 된다
→ 상호배제(Mutual Exclusion) 조건이 깨짐
-
-
현대적인 컴퓨터 아키텍처에서의 피터슨 솔루션
-
상호 배제 → 깨질 수 있음
- flag[i] = true와 turn = j의 순서가 재배치되면, 두 프로세스가 동시에 CS에 들어가는 일 발생
-
진행성 → 깨질 수 있음
- while (flag[j] && turn == j)가 잘못된 시점에 평가되면 모든 프로세스가 불필요하게 계속 기다릴 수 있음
-
한정된 대기 → 보장할 수 없음
- 진행성이 만족되지 않으므로 한정된 대기 또한 만족하지 않음
-
- 피터슨 알고리즘이 현대 컴퓨터 아키텍처에서 올바르게 작동하려면, Memory Barrier(메모리 장벽)을 사용해야 함
메모리 장벽
-
메모리 모델
- 컴퓨터 아키텍처가 응용 프로그램에 대해 보장하는 메모리 동작 방식
-
메모리 모델의 유형
-
강한 순서 모델 (Strongly Ordered)
→ 하나의 프로세서에서 메모리를 수정하면, 즉시 다른 모든 프로세서에 보이게 됨
-
약한 순서 모델 (Weakly Ordered)
→ 한 프로세서에서의 메모리 수정이 다른 프로세서에게 즉시 보이지 않을 수 있음
-
-
메모리 장벽(Memory Barrier)
- 메모리 변경 사항이 다른 모든 프로세서에 전파(가시화)되도록 강제하는 명령어
- 모든 이전의 load/store 명령이 완료된 후에만 다음 load/store 명령이 실행됨
- 결과적으로 CPU나 컴파일러가 명령어를 재배치(reorder) 하더라도, 메모리 배리어는 이전의 저장(store) 작업이 메모리에 기록되고, 다른 프로세서에게 보이도록 한 뒤에만 다음 명령어를 수행하게 만든다.
- 메모리 장벽은 약한 순서 위에서 동작하면서, 그 지점만 강한 순서를 보장하도록 강제하는 장치
-
Memory Barrier는 명령어 재배치로 인한 동기화 문제를 막기 위한 장치이며, 특히 멀티코어 환경에서 공유 메모리의 일관성을 보장하는 데 중요하다.
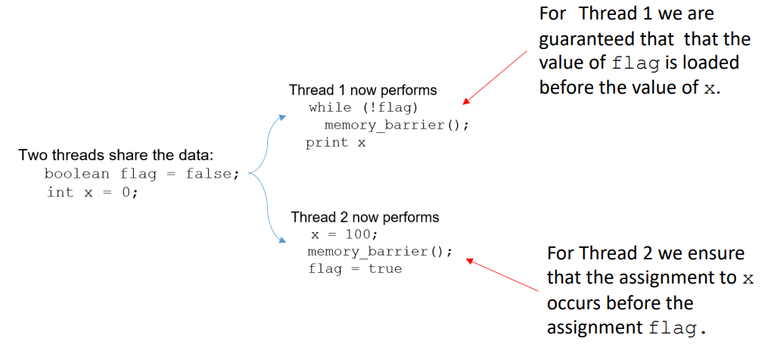
- Thread 2에서 : memory_barrier()는 flag = true를 하기 전에 반드시 x = 100이 완전히 끝남을 보장
- Thread 2에서 : memory_barrier()는 flag 값을 읽은 이후에야 x가 출력됨을 강제함
6.4 동기화 하드웨어
- 피터슨 솔루션은 모두 소프트웨어 기반 해결책에 해당
-
그러나 많은 시스템은 Critical Section 문제 해결을 위한 하드웨어적 지원을 제공함
- 대표적으로 ‘인터럽트 기반 솔루션’ 이 있음
- 하드웨어의 인터럽트 플래그를 직접 조작하는 명령어이므로, 하드웨어 지원에 해당
- 그러나, 선점 없이 끝까지 실행하는 방식이므로 멀티 프로세서 시스템에서 매우 비효율적이며 확장성이 떨어짐
-
동기화 하드웨어(Synchronization Hardware)는 락킹의 하드웨어적 해결책에 해당한다.
- 락킹(locking): 공유 자원(또는 임계 구역)에 둘 이상의 프로세스(또는 스레드)가 동시에 진입하지 못하도록, 진입 시점에 잠금(lock)을 획득하고, 종료 시점에 잠금을 해제하는 동기화 메커니즘
-
앞으로 살펴볼 두 가지의 하드웨어 기반 동기화 방법은 다음과 같다.
- 하드웨어 명령어(Hardware instructions)
- 원자적 변수(Atomic variables)
1️⃣ 하드웨어 명령어
-
현대의 컴퓨터는 다음과 같은 특수한 하드웨어 명령어를 제공한다
- 메모리의 한 워드(word)의 내용을 검사(test)하거나,
- 두 워드의 내용을 원자적으로(atomic) 교환(swap)할 수 있다.
-
대표적인 하드웨어 명령어는 다음과 같다.
TestAndSet()명령어: 두문자를 따 TAS라고 부른다.Compare-and-Swap()명령: 두문자를 따 CAS라고 부른다.
- TestAndSet 명령어
boolean TestAndSet(boolean *target) {
boolean rv = *target; // 현재 값 저장
*target = true; // 값을 true로 설정
return rv; // 이전 값을 반환
}do {
while (TestAndSet(&lock)); // lock이 false일 때까지 대기
// Critical Section
lock = false; // 나올 때 잠금 해제
// 나머지 Section
} while (true);- target에 저장된 값을 읽고, 그 값을 true로 바꾼 뒤, 원래 값을 반환한다.
- 이 연산은 원자적으로 이루어지며, 다른 스레드가 중간에 끼어들지 않는다.
-
피터슨 솔루션과의 차이점
구분 피터슨 알고리즘 TestAndSet 기반 알고리즘 동기화 방식 소프트웨어적 (flag[], turn) 하드웨어 명령어 기반 ( TestAndSet)변수 구성 flag[2],turnflag = 진입 의사 표시 turn = 우선권 |
lock하나 (boolean) 내가 들어가고 나서 lock = true 변경 이 때 다른 프로세스는 들어갈 수 없음 | | 제어 방법 | 상대방 의사(flag[j]) + 양보(turn) 조합으로 접근 통제 | 하나의 전역 잠금 변수(lock) 를 원자적으로 조작하여 진입 통제 | -
임계구역 진입 예시
🅰️ 예를 들어, 스레드 A가 처음에 도착하면
lock == false니까:
rv = false; // 현재 값 읽음 *lock = true; // 내가 들어갈 거니까 잠금 return false; // 이전 값 반환→
TestAndSet(&lock)의 결과는false→
while(false)니까 while 루프를 빠져나감 (임계구역 진입)🅱️ 동시에 스레드 B도 들어오면?
- 이제
lock == true상태이므로:
rv = true; // 이전 값은 true *lock = true; // 그대로 true return true;→
TestAndSet(&lock)의 결과는true→
while(true)니까 루프 안에서 기다림 (즉, 임계구역에 못 들어감)- 즉, TestAndSet 코드가 하는 일은 문이 열려있는지 확인하면서, 동시에 문고리를 잠그는 일이다. (또한, 문고리 잠그기는 문의 현재 상태(열림/닫힘)와 상관 없이 수행한다.)
- TestAndSet을 이용한 Critical Section 코드는 Mutual Exclusion(상호 배제) 조건을 만족함
-
하지만 이 방식은 Bounded Waiting(한정된 대기) 조건을 만족하지 못함
- 여러 스레드가 동시에 while(TestAndSet(&lock)) 을 수행하면 어떤 스레드는 계속해서 크리티컬 섹션에 진입할 수도 있고, 어떤 스레드는 무한히 기다리게 되는 경우도 발생할 수 있음.
- 즉, 공정성이 보장되지 않는다. (피터슨 솔루션과 비교했을 때, 우선권(turn) 유무의 차이로 발생)
- Compareandswap 명령어
int compare_and_swap(int *value, int expected, int new_value) {
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}int lock = 0; // 초기 상태는 잠금이 없는 상태
do {
while (compare_and_swap(&lock, 0, 1) != 0) // 잠겨 있으면 계속 기다림 (busy wait)
// Critical Section
lock = 0; // 끝나고 나면 잠금 해제
// 나머지 Section
} while (true);- 현재 값(
value)을temp에 저장 - 만약
value == expected면,value = new_value로 값을 바꿈 - 어쨌든
temp를 반환함 (즉, 교체되었는지 여부를 알려줌) - 이 연산은 원자적으로 이루어지며, 다른 스레드가 중간에 끼어들지 않는다.
-
임계구역 진입 예시
🅰️ 스레드 A가 먼저 도착한 경우
A가 다음을 호출:
// 현재 lock = 0 (초기 상태) compare_and_swap(&lock, 0, 1);- 현재
lock == 0이므로 →expected와 일치 - →
lock = 1로 바뀜 (잠금 성공) - → 반환값은
0 - →
while (0)→ 루프 탈출 (임계구역 진입 성공)
🅱️ 스레드 B가 그 직후 도착한 경우
B가 호출:
// 현재 lock = 1 (A가 사용중) compare_and_swap(&lock, 0, 1);- 현재
lock == 1이므로 →expected와 불일치 - →
lock값은 그대로 유지 (변화 없음) - → 반환값은
1 - →
while (1)→ 계속 반복 (임계구역 진입 실패)
- 현재
- compareandswap을 이용한 Critical Section 코드는 Mutual Exclusion(상호 배제) 조건을 만족함
-
하지만 이 방식 또한 Bounded Waiting(한정된 대기) 조건을 만족하지 못함
- 누구도 "다음엔 너 차례야" 라는 우선권 개념이 없음
- 운 나쁜 스레드는 계속 기다리게 됨
TestAndSet 을 활용한 한정된 대기 조건을 만족하는 알고리즘
do{
waiting[i] = True; // True : 임계구역을 사용하기 위해 대기중
key = True;
while(waiting[i]==True && key==True)
{
key = TestAndSet(&lock);
}
// False :
// 1. 임계구역에 들어왔기 때문에 더이상 대기 하지 않음
// 2. 애초부터 임계구역을 사용하지 않기 때문에 False로 저장됨
waiting[i] = False;
/* Critical Section */
j = (i+1) % n; // j : i번째 프로세스의 다음 프로세스
// 반복문 탈출 조건
// 1. 순회를 계속하여 i번재 프로세스로 되돌아 온경우 (j == i )
// 2. 다른 프로세스가 임계구역을 사용하기 위해 대기하는 경우 (waiting[j]==True)
while((j != i) && waiting[j]==False)
{
j = (j+1) % n; // 다음 프로세스로 이동
}
if(j == i) // 다른 프로세스가 임계구역을 사용하기 위해 대기하고 있지 않은 경우
{
lock = False;
}
else // 다른 프로세스가 임계구역을 사용하기 위해 대기하고 있는 경우
{
// j번째 프로세스는 while문을 탈출하여 임계구역을 사용하게됨
// lock==true, 다른 프로세스가 임계구역을 여전히 사용중이므로 lock은 여전히 True이다.
waiting[j] = False;
}
}while(True);2️⃣ 원자적 변수 (Atomic Variables)
- 일반적으로
compare-and-swap과 같은 명령어는 하드웨어 수준의 원자적 명령어로, 다른 동기화 도구를 구성하는 기본 블록(building block) 으로써 사용된다. -
앞서 언급한 다른 동기화 도구 중 하나가 원자적 변수(atomic variable)이다.
- 이는 정수나 불리언 같은 기본 데이터 타입에 대해 원자적(=중단 없이)으로 값을 업데이트할 수 있게 해주는 도구이다.
- 즉, compareandswap 등의 원자적 명령어를 활용해서 만들어진 고수준의 동기화 도구를 원자적 변수라고 부른다.
-
예를 들어,
sequence라는 변수가 atomic variable이라고 가정해보자.increment()는sequence에 대해 수행되는 연산이다.
increment(&sequence);- 이 명령은
sequence를 다른 스레드의 방해 없이 (= 중단 없이, 안전하게) 증가시킬 수 있도록 보장한다. - increment() 함수는 다음과 같이 구현할 수 있다.
void increment(atomic_int *v) { int temp; do { temp = *v; // 현재 값 읽기 } while (temp != compare_and_swap(v, temp, temp + 1)); }
6.5 뮤텍스 락 (Mutex Locks)
- 이전에 살펴본 하드웨어 기반 해법들은 복잡하고, 응용 프로그램 개발자들이 사용하기에는 어려웠다.
-
그래서 운영체제 설계자들은 임계 구역 문제 해결을 위한 소프트웨어 도구를 개발하였음
- 가장 간단한 도구가 Mutex Lock
- 이후에 나올 세마포어와는 다르게 하나의 스레드만을 제어할 수 있다.
- 바이너리 세마포어라고 부를 수 있음
뮤텍스 락의 개념
-
Mutex Lock은 세마포어 값이 0 또는 1을 가지는 이진 세마포어(Binary Semaphore)
- 잠금이 가능한지 여부를 나타내는 불리언 변수를 사용
- Mutex Lock은 다른 프로세스로부터 임계구역을 보호하고 경쟁 상태(race condition)을 예방한다.
-
뮤텍스는 “단순히 잠금을 거는 도구”가 아니라, 운영체제 또는 라이브러리가 내부에서 어떻게 구현하느냐에 따라 정책적으로 공정성을 보장할 수 있는 도구이기도 하다.
- CAS나 TAS가 가진 ‘한정된 대기’ 문제의 해결 가능
-
Mutex Lock을 이용하는 프로세스들은 임계구역 입장 전 Lock을 얻어야 하고 임계 구역을 나가게 되면 Lock을 해제하여야 한다.
img1.daumcdn.png
-
임계 구역을 보호하기 위해서는:
- 먼저 acquire()를 호출하여 락을 획득하고
- 작업이 끝난 후 release()를 호출하여 락을 해제해야 한다.
-
available(lock을 얻을 수 있는지 없는지 나타내는 Boolean 변수)를 사용한다.
- available = true : 임계 영역 입장이 가능함
- available = false : 임계 영역 입장이 불가능함. 바쁜 대기(Busy Waiting)을 수행함
-
acquire()와 release()는 원자적으로 실행되어야 한다.

- 즉, 중간에 다른 프로세스가 끼어들 수 없어야 한다.
- 이러한 원자성은 보통
compare-and-swap같은 하드웨어 명령어로 구현된다.
-
하지만 이 방식은 busy waiting(바쁜 대기)을 필요로 한다.
- 즉, 락을 얻을 수 있을 때까지 계속 루프를 돌며 CPU를 소비한다.
- 이 Lock 방식(짧은 변수 안에서 락 변수를 계속 검사하며 회전하는 방식)을 스핀락(Spinlock)이라 부른다. (즉 스핀락 ⊂ 바쁜 대기)

스핀락(Spinlock)
- 바쁜 대기(Busy Waiting) 방식을 이용한 뮤텍스 락의 잠금 유형
- 프로세스는 lock을 얻을때까지 대기하는 동안 반복문을 반복한다.
-
스핀락의 장점
- lock을 얻기 위해 대기하는 동안 문맥 교환(Context Switch)가 요구되지 않는다. 왜나하면 문맥 교환은 상단한 시간이 소요될 수 있기 때문이다.
- 스핀락은 멀티코어 시스템의 특정한 상황에서 락킹(locking)을 위한 선호되는 선택이 될 수 있다.
- 하나의 쓰레드가 하나의 CPU 코어에서 스핀을 하는 반면 다른 쓰레드는 다른 CPU코어에서 임계 영역의 작업을 수행할 수 있다.
뮤텍스 락 예제
#include <stdio.h>
#include <pthread.h>
int sum = 0; // a shared variable
pthread_mutex_t mutex;
void* counter(void* param)
{
for(int k=0; k<10000; k++)
{
/* entry section */
pthread_mutex_lock(&mutex);
/* critical section */
sum++;
/* exit section */
pthread_mutex_unlock(&mutex);
/* remainder section */
}
pthread_exit(0);
}
int main()
{
pthread_t tid1, tid2;
pthread_mutex_init(&mutex, NULL);
pthread_create(&tid1, NULL, counter, NULL);
pthread_create(&tid2, NULL, counter, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
printf("sum = %d\n", sum); // 20000
}-
mutex lock을 사용하기 위해서 pthread 라이브러리를 사용한 예제
- pthreadmutext mutex : 뮤텍스 락에서 lock 역할을 수행한다.
- pthreadmutexlock(&mutex) : mutex라는 이름의 lock을 얻기 위해 시도한다. 다른 스레드가 이미 임계 영역에서 작업중이면 바쁜 대기를 수행한다.
- pthreadmutextunlock(&mutex) : 스레드가 임계영역을 다 사용하였다면 lock을 해제한다.
6.6 세마포어 (Semaphore)
- 뮤텍스 락과 마찬가지로 여러 스레드가 동시에 공유자원에 접근하는 것을 막기 위한 동기화 도구
-
세마포어의 사용 이유
- TAS, CAS 등의 하드웨어 기반 해결안은 사용하기 복잡하기 때문
-
세마포어의 종류
- 이진 세마포어 (mutex lock과 기능적으로 동일)
- 카운팅 세마포어 (0..N)
세마포어의 연산
-
wait() 과 signal()
-
wait()

- 스레드가 임계구역에 들어가기 위해 호출하는 연산
- 다른 스레드가 임계구역 내에서 작업중이면 대기한다.
-
signal()

- 스레드가 임계구역에 작업을 마치고 세마포어를 해제하는 연산
-
- 두 연산이 수행할 때 세마포어의 값을 수정하는 동안 다른 스레드가 선점할 수 없다.
- wait()과 signal() 연산은 원자적(atomically)으로 수행된다.
세마포어의 구현
-
바쁜 대기 (busy waiting) 방식으로의 구현
wait(S){ while(S <= 0) // 이용가능한 세마포어가 없는 경우 ; // busy wait S--; }signal(S){ S++; }- 한 프로세스가 임계 구역에 있을 때, 다른 프로세스가 자신의 임계 구역에 진입하려고 하면 진입 코드에서 계속해서 반복하며 대기해야 한다.
- 구현 코드가 짧다.
- 하지만, 애플리케이션이 Critical Section에서 많은 시간을 보내야 할 수 있다. → 좋은 해결책이 아님
-
Block & Wakeup 방식으로의 구현
wait(semaphore *S){ S->value--; if(S->value < 0){ S->list.add(P); // 현재 프로세스를 리스트에 넣음 block(); } }signal(semaphore *S){ S->value++; if(S->value <= 0){ S->list.poll(); wakeup(P); } }- 각 세마포어는 연결된 Waiting Queue(대기 큐)가 존재
-
대기 큐의 각 원소에는 다음과 같은 두 개의 데이터 항목이 존재한다
typedef struct{ int value; struct process *list; }semaphore;- value : 정수형 데이터
- pointer : 리스트 내 다음 레코드를 가리키는 포인터
-
두 가지 주요 연산이 존재한다
- block: 이 연산을 호출한 프로세스를 해당 세마포어의 Waiting Queue에 추가한다.
- wakeup: 대기 큐에 있는 하나의 프로세스를 제거하여, Ready Queue에 넣는다.
생존성
- 프로세스는 뮤텍스 락이나 세마포어 같은 동기화 도구를 획득하려고 시도하는 동안, 무기한으로 대기해야 할 수도 있다.
- 이러한 무기한 대기(indefinite waiting)는 이 장의 초반에 언급된 진행성(progress) 및 한정된 대기(bounded waiting) 기준을 위반하는 것에 해당한다.
- Liveness(생존성)는 시스템이 프로세스들이 실제로 작업을 진행할 수 있도록 보장하기 위해 충족해야 하는 일련의 특성들을 의미한다.
- 따라서 무한한 대기는 생존성 실패(liveness failure)의 한 예가 된다.
생존성 실패
-
데드락 (Deadlock)
-
두 개 이상의 프로세스가 서로가 발생시켜야만 하는 이벤트를 기다리며 멈춰 있는 상태

-
즉, 서로가 서로를 기다리기 때문에 아무도 앞으로 나아가지 못한다.
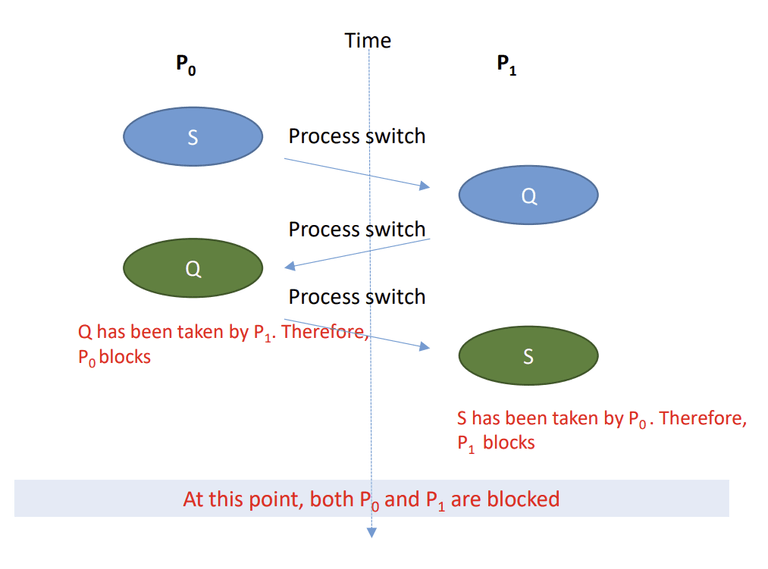
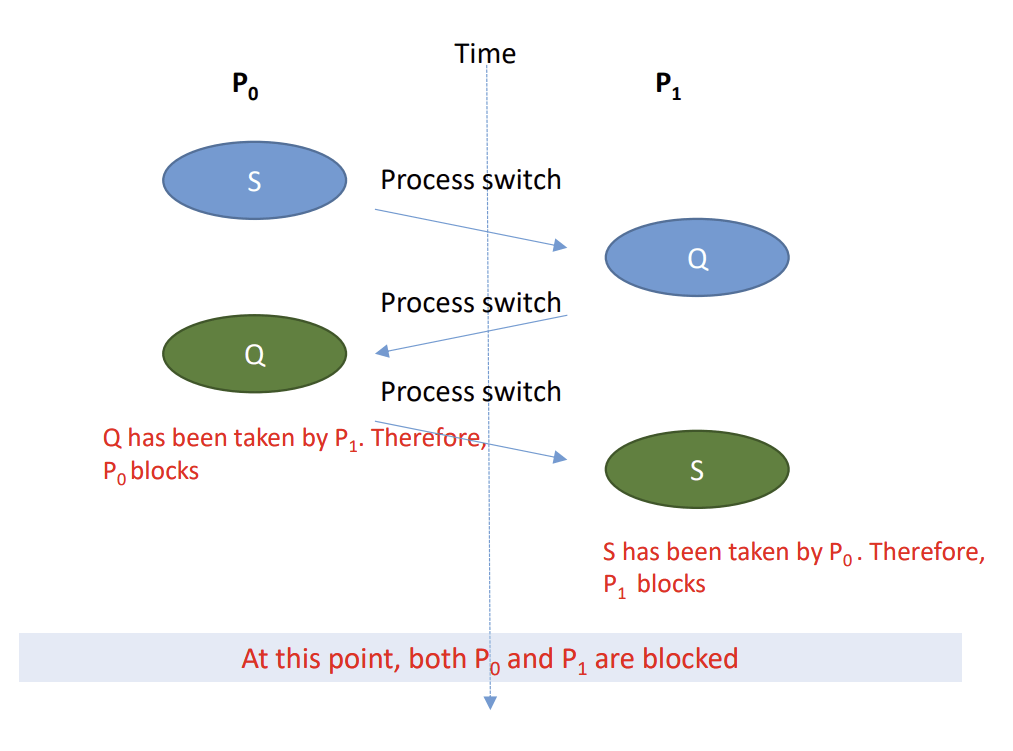
- 이 먼저 자원 S를 획득한다.
- 프로세스 전환이 일어나고, 이 실행되어 자원 Q를 획득한다.
- 다시 프로세스 전환이 일어나고, 이 Q를 요청한다. → 대기 상태 진입
- 다시 프로세스 전환이 일어나고, 이 S를 요청한다. → 대기 상태 진입
- 데드락이 발생하게 되었음
-
-
기아 상태 (Starvation)
- 무기한 차단 (Indefinite blocking): 어떤 프로세스가 세마포어 큐에 매달린 채로 영원히 제거되지 않는 상황을 말한다.
- 예를 들어, 큐에서 프로세스를 LIFO(후입선출) 방식으로 제거할 경우, 일부 프로세스는 계속 뒤로 밀려서 실행되지 못할 수 있다.
-
우선순위 역전(Priority Inversion)
- 낮은 우선순위 프로세스가 높은 우선순위 프로세스에 필요한 lock을 보유하고 있을 때 발생하는 스케줄링 문제
-
우선순위 계승 (Priority Inheritance Protocol)
- 특정 프로세스가 우선순위가 더 높은 프로세스의 자원을 가지고 있을 때, 자원을 요구하는 프로세스만큼 프로세스의 우선순위를 높여주는 기법
-
규칙
- 자원이 사용 중이면 Process는 Block 됨
- 자원이 사용 가능하면 Process는 자원을 소유
- 우선순위가 높은 Process가 같은 자원을 요청하면 기존 Process의 우선 순위는 자원을 요청한 Process의 우선 순위로 높아짐
- Process가 자원을 반환하면 원래의 우선 순위로 돌아옴
6.8 모니터 (Monitors)
-
세마포어는 잘못 사용하면 발견하기 어려운 타이밍 에러를 발생시킬 수 있다.
- 타이밍 에러(timing errors): 어떤 특정한 실행 순서 상에서, 언제나 발생하지도 않으며 탐색하기도 쉽지 않은 오류 중 하나
- 세마포어를 사용한 이유는 생산자-소비자 문제를 해결하기 위함이었으나, 여전히 매우 드물게 이러한 오류가 발생할 수 있음
- 모니터를 통해 이러한 타이밍 오류가 일어나지 않도록 예방할 수 있다.
세마포어와 오류
-
세마포어 문제가 발생하는 환경
- 모든 프로세스는 이진 세마포어이며, 1로 초기화된 mutex를 공유한다.
- 각각의 프로세스는 Critical Section에 들어가기 전에 wait(&mutex)를 호출한다.
- Critical Section의 작업을 마친 프로세스는 signal(&mutex)를 호출하여 자원을 반납한다.
- 이 때, wait → signal의 순서를 지키지 않는 경우, 두 개 이상의 프로세스가 동시에 Critical Section에 접근하는 문제가 발생할 수 있다.
-
signal(mutex) → wait(mutex) 순서로 호출한 경우

img1.daumcdn.png -
wait(mutex) → wait(mutex) 또는 signal(mutex) -> signal(mutex) 순서로 호출한 경우

img1.daumcdn.png -
wait(mutex) 또는 signal(mutex) 호출을 하나 또는 둘 다 생략하는 경우

모니터의 개념과 사용법
-
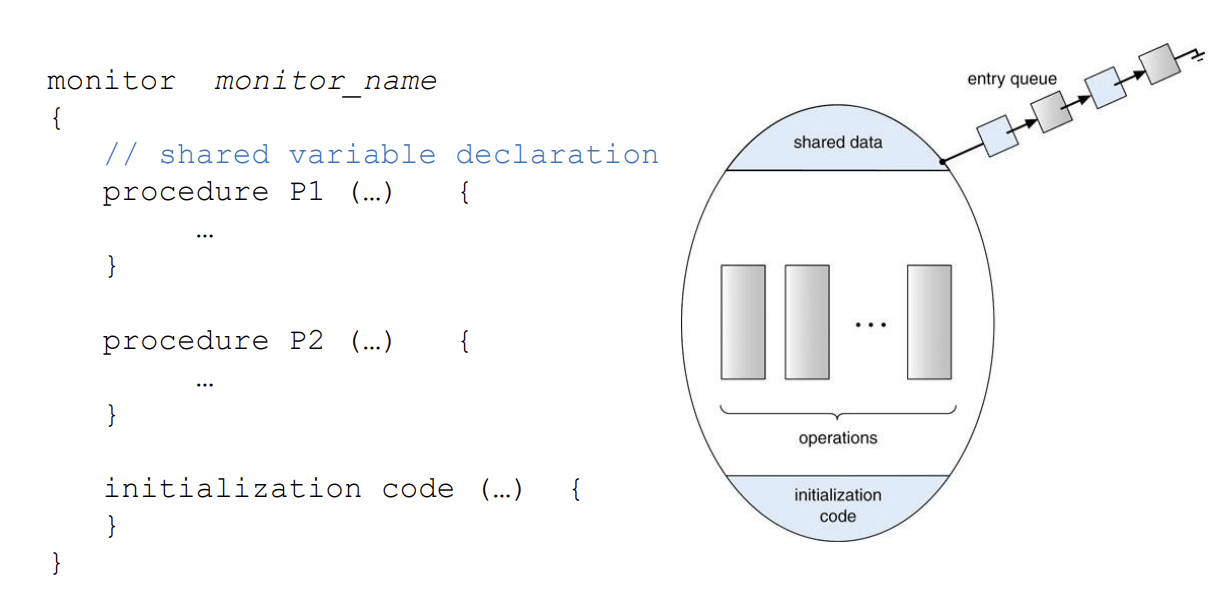
모니터(Monitors) : 프로세스 동기화를 위해 편리하고 효과적인 메커니즘을 제공하는 고수준 추상 데이터 타입(ADT, abstract data type)
- 데이터와 이 데이터를 조작하는 함수들의 집합을 하나의 단위로 묶어 보호한다.
-
모니터 구조물은 모니터 안에 항상 하나의 프로세스만이 활성화되도록 보장한다. 그러므로 프로그래머들은 이와 같은 동기화 제약 조건을 명시적으로 코딩해야 할 필요가 없다.
- 그러나 자신의 주문형 동기화 기법을 작성할 필요가 있는 프로그램을 위해 조건 변수(condition variables)를 선택적으로 사용할 수 있다.
- 모니터 내부에서는 프로그래머가 정의한 일련의 연산(operation)에 대해 상호 배제(Mutual Exclusion)가 자동으로 보장됨
- 추상 데이터 타입으로, 내부 변수들은 해당 프로시저 내부 코드에서만 접근 가능
- 동시에 하나의 프로세스만 모니터 안에서 활성 상태가 될 수 있음
모니터의 구조
- MEQ(Mutual Exclusion Queue) : 모니터에 진입하려는 프로세스들의 큐
-
공유 자원(Shared Preferences) : 모니터 내부에 존재하는 공유자원
- 여러 프로세스들이 순차적으로 접근하여 사용할 수 있다.
-
프로시저(Procedure) : 공유 자원에 접근하기 위한 접근 함수
- 한 프로세스가 프로시저를 사용하여 공유 자원을 사용하고 있다면 다른 프로세스들은 접근할 수 없음
- 초기화 코드 : 공유 자원을 초기화 해주는 코드
- 조건 변수(Condition Variable) : 모니터에 접근하는 프로세스들의 순서를 보장하기 위한 구조물
세마포어를 이용한 모니터 구현
-
변수
semaphore mutex mutex = 1 -
각 프로시저 P에 대해
wait(mutex); … /* P의 본문(body of P) */ … signal(mutex);
조건 변수 (Condition Variables)
-
모니터 형은 자체적으로 동기화 문제를 풀기에 아쉬운 부분이 존재한다.
- 공유 자원에 접근하려는 프로세스 간의 실행 순서를 정의할 수 없기 때문
- 만약 공유 자원을 사용한다면, 권한을 어떤 프로세스에게 주어야 할지 정할 수 없는 문제가 있다.
- 조견 변수는 모니터 내부에서 추가적인 동기화 메커니즘을 제공하기 위해서 정의되었다.
-
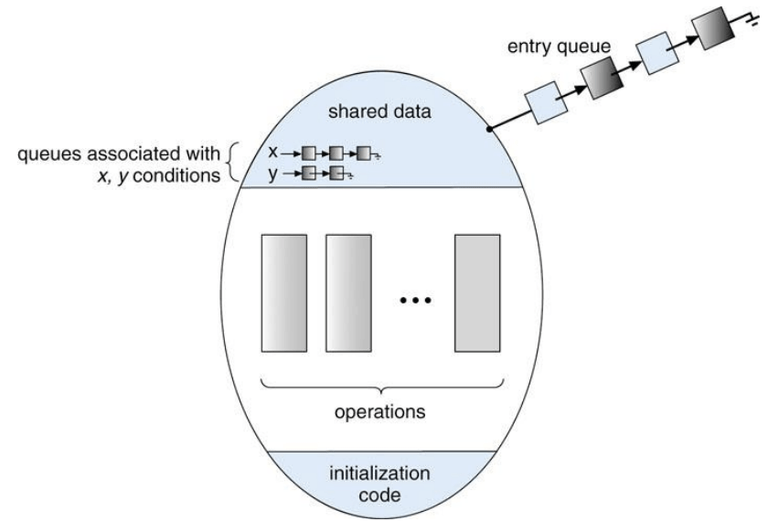
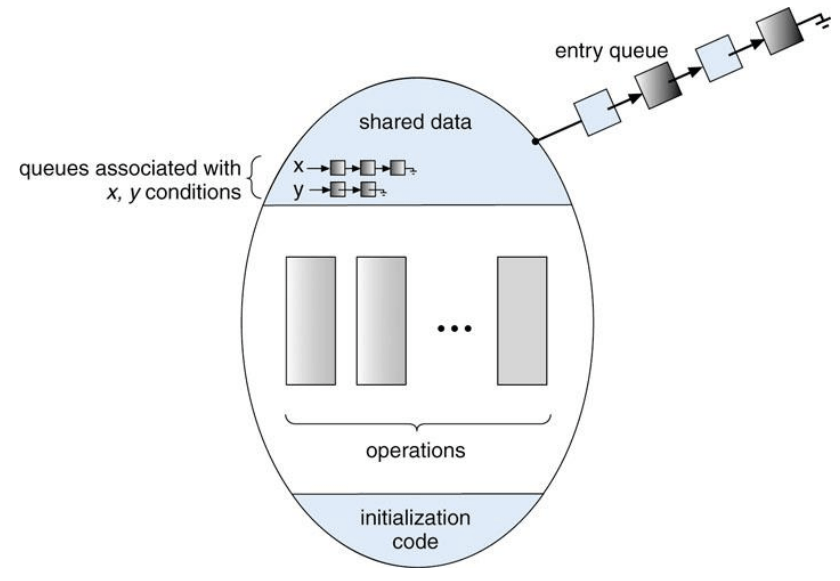
조건 변수의 선언
condition x; // x는 실행 순서를 정하고자 하는 특정 공유 자원과 1:1 대응되는 조건 변수 -
조건 변수(condition variable)에 대한 두 가지 연산
-
x.wait()
- 이 연산을 호출한 프로세스는
x.signal()이 호출될 때까지 일시 정지(suspend)된다.
- 이 연산을 호출한 프로세스는
-
x.signal()
x.wait()를 호출하고 대기 중인 프로세스가 있으면 그 중 한 개를 깨워(resume) 실행 대기 상태로 만든다.- 만약 대기 중인 프로세스가 없다면, 아무런 효과가 없다.
-
조건 변수 사용 예시
- 두 프로세스 P1과 P2를 고려해 보자.
- 이들은 각각 문장 S1과 S2를 실행해야 하며, S1이 S2보다 먼저 실행되어야 한다는 요구사항이 있다.
- P1과 P2에서 각각 호출할 두 개의 프로시저 F1과 F2를 제공하는 모니터를 생성하라.
-
하나의 불리언 변수 done을 선언하고, false로 초기화하라.

-
조건 변수 선택 사항
-
프로세스 P가
x.signal()을 호출하고, 프로세스 Q가x.wait()에서 대기 중이라면, 이후 어떻게 동작해야 할까?- Q와 P는 동시에 실행될 수 없다. Q를 깨운다면 P는 대기해야 한다.
-
-
선택지
- “모니터 안에서 조건 변수(condition variable)를 사용할 때,
signal()이 호출된 뒤 깨워진(wait 중이던) 스레드(Q)와signal()을 호출한 스레드(P) 중 누가 모니터를 먼저 점유해서 실행을 이어가야 하는가?”를 정하는 정책(policy) 에 대한 설명에 해당한다. -
Signal and wait
- P가
x.signal()을 호출하면, 깨울 대상인 Q를 대기 큐에서 꺼낸 뒤 즉시 P 자신이 모니터를 떠나지 않고 기다린다. - 그러면 Q가 먼저 모니터 락을 가져가서 실행을 이어가고, Q가 다른
wait()를 호출하거나 모니터를 완전히 빠져나갈 때까지 P는 대기해야 한다.
- P가
-
Signal and continue
- P가
x.signal()을 호출한 뒤에도 바로 실행을 계속(모니터를 점유한 채로). - 이 동안 Q는 깨졌지만 락을 얻지 못하고 대기 상태를 유지하다가, P가 모니터를 완전히 빠져나가거나 또 다른 조건을 기다리기 위해
wait()를 부르면 그제야 락을 획득해 실행을 재개한다.
- P가
- 두 방식 모두 장단점이 있으므로, 언어 구현자가 결정할 수 있다.
-
Concurrent Pascal의 타협안
- P가
signal()을 호출하면 즉시 모니터를 떠나고(즉, 모니터 락을 해제하고), 바로 Q가 락을 가져가 실행을 재개하도록 설계
- P가
-
다른 언어 구현 사례
- Mesa, C#, Java 등에서도 각기 다른 방식으로 구현되어 있다.
- Signal and wait가 Q를 즉시 실행시켜 응답성을 높이는 대신, 구현이 더 복잡하고 데드락(deadlock) 가능성이 조금 더 높을 수 있고, (hand-off 지점(
wait(next))이 잘못 맞물리면 P와 Q가 서로에게 락을 넘겨주기를 무한히 기다릴 수 있음) - Signal and continue는 구현이 간단하고 P가 일관되게 실행 흐름을 이어가긴 쉽지만, Q가 락을 얻기까지 지연될 수 있다는 장단점이 있다.(즉각적인 hand-off가 없고, 락 해제는 항상 “모니터 메서드 종료” 같은 단일 지점에서 일어나기 때문에 순환 대기의 가능성이 작아짐)
- “모니터 안에서 조건 변수(condition variable)를 사용할 때,
🤔 뮤텍스의 wait/signal 호출 vs. 모니터의 조건 변수 사용
(‘결국 wait/signal을 쓰는 거면 뮤텍스랑 무엇이 다른가?’ 에 대한 질문과 답)
| 구분 | 세마포어 (Semaphore) | 모니터 (Monitor) |
|---|---|---|
| 추상화 수준 | 로우레벨 원시 동기화 수단 | 고수준 추상 데이터 타입(ADT), 데이터와 연산을 하나로 묶음 |
| 락 관리 | wait(mutex) → 임계 구역 → signal(mutex) (명시적) |
프로시저 진입 시 암묵적 lock, 종료 시 암묵적 unlock 자동 수행 |
| 조건 변수 통합 | 별도의 메커니즘 필요 (lost–signal 등 버그 위험) | x.wait()에서 “락 해제+대기”, x.signal()에서 “깨우고 락 재획득”을 원자적으로 처리 |
| 오류 발생 가능성 | 순서·생략 실수 시 교착(deadlock), 경합(race) 등 타이밍 에러 발생 | 락 방출 누락·잘못된 순서 리스크 대폭 감소; 조건 변수로 대기/신호 로직 안전 보장 |
| 모듈화·유지보수성 | 락 로직이 분산되어 코드 가독성 저하 | 동기화 로직이 모니터 내부에 캡슐화되어, 외부에서는 공개된 연산만 호출하므로 코드 유지보수가 용이 |
| 용도 | 리소스 카운팅, 간단 락킹, 범용 원자 교체(CAS 등) | 임계 구역 보호, 복잡한 상태 기반 동기화, 프로듀서-컨슈머, 리더-라이터 등 고수준 패턴 구현에 적합 |
// =========================
// 1) 세마포어 방식 (C-style)
// =========================
semaphore mutex = 1;
semaphore empty = 1;
semaphore full = 0;
int buffer; // 크기 1
// 생산자
void producer(int item) {
wait(empty); // 버퍼에 빈 공간이 있는지
wait(mutex); // 임계 구역 진입
buffer = item; // 버퍼에 아이템 저장
signal(mutex); // 임계 구역 해제
signal(full); // 소비자 깨어남
}
// 소비자
int consumer() {
int item;
wait(full); // 버퍼에 데이터가 있는지
wait(mutex); // 임계 구역 진입
item = buffer; // 버퍼에서 아이템 읽음
signal(mutex); // 임계 구역 해제
signal(empty); // 생산자 깨어남
return item;
}
// =========================
// 2) 모니터 방식 (Java-style)
// =========================
class BoundedBuffer {
private int buffer; // 크기 1
private boolean hasItem = false;
// 암묵적 락: 메서드 진입 시 획득, 종료 시 해제
public synchronized void put(int item) throws InterruptedException {
while (hasItem) { // 버퍼가 가득 차 있으면
wait(); // 자동으로 락 해제+대기
}
buffer = item;
hasItem = true;
notify(); // 기다리는 소비자 하나 깨움
}
public synchronized int get() throws InterruptedException {
while (!hasItem) { // 버퍼가 비어 있으면
wait(); // 자동으로 락 해제+대기
}
int item = buffer;
hasItem = false;
notify(); // 기다리는 생산자 하나 깨움
return item;
}
}
// 사용 예
BoundedBuffer buf = new BoundedBuffer();
// 생산자 스레드는 buf.put(x) 호출
// 소비자 스레드는 buf.get() 호출🅰️ 세마포어를 이용한 모니터 구현
- 변수 선언
semaphore mutex; // (초기값 = 1)
semaphore next; // (초기값 = 0)
int next_count = 0; // 모니터 안에서 signal 후 대기 중인 프로세스 수- 각 함수 P에 대한 치환
wait(mutex);
…
/* P의 본문(body of P) */
…
if (next_count > 0)
signal(next);
else
signal(mutex);-
이렇게 하면, P가 모니터를 빠져나가기 전에
- 이미 깨워놓은 프로세스(next)에 락을 넘겨줄지,
- 아니면 일반 mutex로 락을 돌려줄지 결정한다.
- 이로써 모니터 내 상호 배제가 보장된다.
🅱️ 조건 변수를 이용한 모니터 구현
- 각 조건 변수 x마다 다음의 구조를 가짐
semaphore x_sem; // (초기값 = 0)
int x_count = 0; // x.wait()로 대기 중인 프로세스 수- x.wait() 구현
x_count++;
if (next_count > 0)
signal(next);
else
signal(mutex);
wait(x_sem); // x.signal()을 기다린다
x_count--;- x.signal() 구현
if (x_count > 0) {
next_count++;
signal(x_sem); // x.wait() 중인 프로세스 하나를 깨운다
wait(next); // 깨어난 프로세스가 mutex를 넘겨줄 때까지 대기
next_count--;
}- 이렇게 하면 “signal”과 “wait” 방식 간의 교착 없이, 모니터 내 상호 배제와 조건 변수의 올바른 동기화를 모두 구현할 수 있다.
모니터 내 프로세스 재개
- 조건 변수 x에 여러 프로세스가 대기 중이고,
x.signal()이 실행되면 어떤 프로세스를 재개해야 할까? - FCFS(First-Come, First-Served: 선입선출) 방식은 종종 적절하지 않다.
-
이를 보완하기 위한 조건부 대기(conditional-wait) 구문 형태:
x.wait(c)- 여기서 c는 우선순위 번호를 나타낸다.
- 가장 작은 번호(가장 높은 우선순위)를 가진 프로세스가 다음에 스케줄되어 실행된다.
단일 자원 할당 (Single Resource Allocation)
- 프로세스들이 경쟁하는 단일 자원을, 프로세스가 그 자원을 사용할 최대 시간을 나타내는 우선순위 숫자(priority number)를 이용해 할당한다.
R.acquire(t);
…
// 자원 접근 및 사용
…
R.release();-
여기서
R은ResourceAllocator타입의 인스턴스이고,t는 프로세스가 자원을 사용할 계획인 최대 시간을 의미한다.

